Falschmeldungen, manipulierte Bilder und KI-generierte Inhalte verbreiten sich im Internet rasend schnell. In den Nachrichtenportalen verschwimmen oft die Grenzen zwischen Fakt und Fiktion. Nutzerinnen und viele fragen sich: “Kann ich dieser Quelle trauen?“
Die Idee: Ein KI-Plugin für den Browser
Ziel des Projekts ist die Entwicklung eines datenschutzfreundlichen Browser-Plugins, das mithilfe lokal ausgeführter KI-Modelle Texte und Bilder analysiert und bewertet. Der Fokus liegt dabei auf einer vollständig lokal arbeitenden Lösung, die ohne Serververbindung auskommt.
Im Rahmen der Forschung wurde ein Browser-Plugin mit lokalem Backend als Prototyp entwickelt, das Text- und Bildinhalte direkt auf besuchten Webseiten analysiert. Sowohl Nutzerinnen und Nutzer als auch die integrierten KI-Modelle können über eine lokale API mit dem System interagieren.

Zur Analyse kommt die multimodale KI LLaVA (Large Language and Vision Assistant) zum Einsatz, die sowohl sprachliche als auch visuelle Informationen verarbeitet. Beim Start des Plugins kann der Nutzer auswählen, ob der Text der aktuellen Seite oder ein Bild überprüft werden soll. Der jeweilige Inhalt wird dann an das lokale Flask-Backend übergeben, das die Inferenz durchführt und eine Bewertung zurückgibt.
Wie das Plugin funktioniert
Ein Python-Skript im Flask-Backend übernimmt die Auswertung der vom Browser-Plugin übermittelten Inhalte. Dabei wird überprüft, ob der erkannte Text oder das Bild typische Merkmale von Desinformation aufweist.
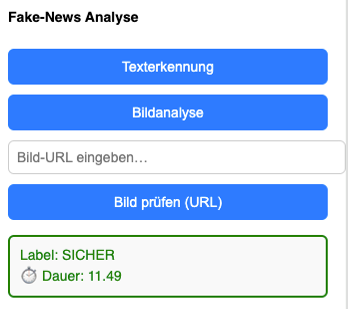
Nach Abschluss der Analyse werden die Ergebnisse im Plugin-Fenster visuell dargestellt. Das System signalisiert den Befund: sicher, unsicher oder verdächtig. So können Nutzerinnen und Nutzer auf einen Blick erkennen, wie vertrauenswürdig der betrachtete Inhalt einzuschätzen ist.
Ein Blick in die Zukunft
In mehreren Testreihen zeigte sich, dass die lokal ausgeführten LLaVA-Modelle sowohl bei Text- als auch bei Bildanalysen zuverlässige Ergebnisse liefern. Besonders das Modell LLaVA 7b erwies sich als effizient und praxistauglich: Es erkannte rund 87 % der manipulativen Texte und KI-generierten Bilder korrekt, bei moderatem Ressourcenverbrauch. Die größeren Varianten LLaVA-13B und LLaVA-34B erreichten zwar eine noch höhere Genauigkeit (bis zu 92 %), benötigten dafür jedoch deutlich mehr Speicher und Rechenleistung.
Die Tests verdeutlichten zugleich: Desinformation entwickelt sich weiter – neue, von generativer KI erstellte Inhalte sind immer schwerer zu entlarven. Einzelne Analyseverfahren reichen daher nicht aus, um alle Täuschungsstrategien zu erkennen.
Ziel der weiteren Forschung ist es, den Ansatz um eine kombinierte Bewertung von Text- und Bildinhalten zu erweitern und die Modelle gezielt mit deutschsprachigen Datensätzen zu fine-tunen. So soll die Erkennungsgenauigkeit erhöht werden, ohne dass die Nutzerfreundlichkeit und lokale Verarbeitung beeinträchtigt werden.